
Scale IoT development faster with our 7-decision framework. Discover which architecture, hardware, and security choices prevent costly pivots later.
How to Approach IoT Development in 2026: A Step-by-Step Roadmap

Your sensors are collecting data across the warehouse floor, the fleet, or the production line — and most of it is either siloed, underutilized, or generating operational noise instead of insight. The decision pressure is real: cloud-native or edge-first, which connectivity protocol survives the next five years, how to avoid a fragmented tech stack that becomes unmaintainable by year two.
This roadmap orders the seven decisions that determine whether your iot development program scales or stalls. Architecture commitments first. Hardware specification second. Data pipelines third. AI integration fourth. Platform selection fifth. Security and lifecycle sixth. Phased execution last. Reverse that order and you spend the next 18 months retrofitting answers you should have written down in week one.
Table of Contents
- Anchor Your IoT Architecture Before Writing a Line of Code
- Specify the Hardware and Sensor Stack That Won't Force a Rewrite
- Engineer the Data Pipeline From Sensor Edge to Analytics Layer
- Layer Predictive AI Onto Your IoT Data — The 2026 Baseline
- Evaluate IoT Platforms and Frameworks Against Your Actual Constraints
- Build Security, Compliance, and Maintenance Into the Design — Not the Backlog
- Execute the Phased Roadmap — Weeks, Roles, and Go/No-Go Triggers
Anchor Your IoT Architecture Before Writing a Line of Code
Architectural commitment in week one shapes cost structure, scalability ceiling, and team composition for the next 36 months. The teams that skip this step and start procuring sensors discover, around month nine, that the architecture chose itself — usually badly. You inherit whatever your first hardware vendor's reference design implied, and unwinding that decision means rewriting firmware fleet-wide.
Three architectures dominate production deployments. Each has a use case where it wins and a specific failure mode that ends the program.
| Architecture | Best Use Case | Latency Profile | Connectivity | Primary Failure Mode |
|---|---|---|---|---|
| Cloud-Centric | High-volume telemetry, non-critical timing | 200ms–2s+ | Reliable, high-bandwidth | Breaks on intermittent connectivity |
| Edge-First | Real-time control, safety systems, low-bandwidth sites | <50ms local | Minimal upstream | Limited cross-site analytics |
| Hybrid (Edge + Cloud + ML) | Production-grade industrial/fleet | Tiered local + cloud | Tolerates intermittency | Operational complexity if layers blur |
Cloud-centric designs stream all sensor data to AWS, Azure, or GCP for processing. They work when latency tolerance sits above 200ms and connectivity is reliable. They fail decisively on offshore rigs, mobile fleets, and rural facilities — anywhere a dropped uplink means lost data or stalled control loops.
Edge-first designs run processing on gateways or directly on the device. This is mandatory when network bandwidth is constrained or when local decision-making — safety shutoffs, real-time control loops, vibration analysis — cannot tolerate the round-trip latency of cloud inference. The trade-off is firmware complexity: every device becomes a small distributed system that needs lifecycle management.
Hybrid (cloud + edge + on-device ML) is now the default production pattern, not a niche choice. According to ARDURA's 2026 IoT software guide, production-grade IoT systems decompose into seven layers — device, firmware, gateway, network, cloud, application, and ML — and treat cloud, edge gateway, and on-device ML as standard components rather than optional add-ons. Edge handles real-time inference and buffering. Cloud handles aggregation, model training, and long-term storage.
The same source identifies a recurring under-investment pattern: teams pour effort into cloud and application layers while neglecting firmware and gateway layers, which then bottleneck scalability six months into production. That sequencing inverts the actual risk surface. A misengineered gateway layer affects every device behind it.
Three decision criteria narrow your choice. First, data volume per device per day — a vibration sensor on a CNC machine generating 10kHz waveforms cannot reasonably ship raw samples to the cloud, so edge processing is non-negotiable. Second, latency tolerance — anything under 200ms forces processing closer to the sensor. Third, connectivity reliability — sites with under 95% uplink availability require local buffering and decision logic regardless of latency requirements.
Apply these to a concrete example. A soil moisture sensor reporting every 15 minutes over NB-IoT is a clean fit for cloud-centric — tiny payloads, generous latency budgets, multi-year battery life. A protective relay on a substation transformer is the opposite end: sub-cycle decision time, no cloud round-trip tolerable, hybrid with edge inference is the only viable pattern. Robologics Lab frames this as multi-stage hardware, network, and cloud integration that demands validation at each layer rather than a single architectural bet.
Write the architecture decision down before you order hardware. Put it in an Architecture Decision Record. Have your embedded lead, cloud lead, and operations sponsor sign it. The cost of changing this decision after pilot deployment is roughly an order of magnitude higher than the cost of debating it for two extra weeks.
Specify the Hardware and Sensor Stack That Won't Force a Rewrite
Hardware selection is where iot development programs leak money fastest. The pattern is consistent: teams over-spec to hedge against future requirements, then discover that the future requirements either never materialized or required different capabilities entirely. The discipline is matching every device to its actual workload, not to the most demanding device in the fleet.
Three hardware tiers cover most production scenarios.

Microcontroller class — Arduino, ESP32, STM32 — sits at sub-$10 BOM with milliwatt power draw. This tier handles constrained sensors with intermittent reporting: temperature, humidity, simple counters, magnetic switches. The constraint is honest: MCUs cannot run modern ML inference reliably and are limited to lightweight protocols. The GitHub IoT roadmap maintained by Mahmood Fathy treats this tier as the entry point for sensor work where compute lives upstream.
Embedded Linux class — Raspberry Pi-class boards, NVIDIA Jetson Nano — runs from $35 to $500. These devices support Python and Node.js runtimes and can execute TensorFlow Lite or ONNX models locally. They become mandatory when devices need on-device inference, richer application logic, or local protocol bridging beyond what an MCU can sustain.
Industrial gateways run $300 to $3,000+, mount on DIN rail, and translate multiple protocols — Modbus, OPC-UA, MQTT, BACnet — often with cellular failover built in. They are required for brownfield retrofits where legacy equipment speaks proprietary protocols. If you are integrating with industrial robotic systems or PLC-driven production lines installed in the last twenty years, the gateway tier is non-negotiable.
Connectivity protocol choice should follow device class, not the other way around. MQTT and MQTTS are the default for telemetry — small headers, pub/sub semantics, broker-mediated. Both major IoT roadmap videos recommend MQTT over HTTP for any continuous reporting scenario, citing efficiency and broker ecosystem maturity. LTE-M suits mobile assets and fleets needing roughly 1Mbps bandwidth with voice handoff and global carrier support. NB-IoT wins for stationary low-bandwidth sensors — utility meters, agricultural probes — with excellent building penetration and 10+ year battery life feasible at low duty cycles. 5G is the answer when you need AR-assisted maintenance, dense sensor environments above 10,000 devices/km², or video-grade telemetry. LoRaWAN is the private-network option: multi-kilometer range, sub-1% duty cycle, no cellular contract, ideal for campus deployments. Telnyx flags 5G and edge connectivity as core 2026 themes, particularly for industrial predictive maintenance use cases.
Consider a representative scenario. A manufacturing client specifies industrial-grade gateways with full 5G support across 200 stations when 180 of them only need NB-IoT-grade telemetry — slow-changing temperature, occasional alarms, daily counter rollups. The over-spec adds roughly $400K in hardware cost and ongoing carrier fees that deliver no operational uplift. That capital should have funded the predictive analytics layer that would actually generate ROI. This scenario is illustrative, not statistical — but most enterprise IoT programs contain at least one decision like it.
Hardware Selection Checklist
- Match processor tier to inference location. Cloud-centric architecture? An MCU suffices. On-device ML? Embedded Linux minimum, often with a dedicated accelerator. Document the inference plan before ordering.
- Validate protocol breadth before purchase. Brownfield sites need gateways that translate Modbus, OPC-UA, and BACnet. Catalog every legacy protocol in scope during architecture phase, not after commissioning.
- Specify connectivity per device class, not per fleet. Stationary, low-bandwidth assets get NB-IoT. Mobile or high-bandwidth assets get LTE-M or 5G. Uniform connectivity specifications waste roughly 30–60% of carrier cost in mixed fleets.
- Calculate power budget against deployment lifetime. Battery-powered devices in remote locations must achieve 5–10 year life through duty cycling and protocol efficiency. Run the math on annual messages × payload size × radio energy before specifying battery chemistry.
- Avoid vendor-locked firmware toolchains. Prefer SoCs with open SDKs — ESP-IDF, Zephyr, FreeRTOS — over proprietary stacks that bind you to a single chipset vendor's roadmap.
- Demand SBOMs from every component vendor. Mandatory for downstream CVE tracking. A vulnerability in a widely-deployed MQTT library becomes your problem within 48 hours of disclosure — and you cannot patch what you cannot inventory.
Specifying every device to its actual workload — not to the most demanding device in the fleet — is the single highest-leverage cost decision in an IoT program.
Engineer the Data Pipeline From Sensor Edge to Analytics Layer
A clean pipeline is the precondition for everything downstream — dashboards, models, alerts, compliance reports. Garbage in produces alerts operators ignore, which is functionally worse than no alerts at all. Sequence the five stages deliberately.
Step 1 — Ingestion at the edge. Translate native device protocols (Modbus, OPC-UA, proprietary serial) into MQTT at the gateway. Buffer locally during connectivity loss so that a 90-minute uplink outage does not equal 90 minutes of lost data. Broker selection follows scale: Mosquitto is lightweight and single-tenant, suitable for sites with under 10,000 devices. EMQX clusters horizontally and handles millions of connections, the right answer for utility-scale or city-scale deployments. HiveMQ ships with enterprise SLAs and integrates well with regulated environments. Managed alternatives — AWS IoT Core, Azure IoT Hub — offload broker operations entirely. Full-stack IoT engineering content treats broker selection as a core architectural decision, not an implementation detail.
Step 2 — Routing decision (edge vs. cloud). Define explicit rules: high-frequency raw data — 1kHz+ vibration waveforms, current-draw signatures — stays on the edge. Aggregated rollups (1-minute means, 1-hour percentiles, daily totals) go to cloud. Anomalies trigger immediate cloud forwarding regardless of bandwidth budget. This routing logic determines monthly egress cost and effectively determines your cloud bill. Apply intelligent automation logic at the routing layer so that conditional forwarding rules can be updated centrally rather than reflashed device-by-device.
Step 3 — Storage tier selection. Three tiers, each tuned to access pattern. Hot data — last 7 to 30 days — lives in a time-series database, either on the edge (InfluxDB, TimescaleDB) for local analytics or in the cloud for fleet-wide views. Warm analytical data lives in a cloud data lake (S3 or Azure Blob with Parquet or Iceberg format) optimized for SQL queries and ML training pulls. Cold archival data — compliance retention, accessed quarterly or less — sits in S3 Glacier or Azure Archive at roughly 1/10th the cost of standard cloud storage. Mixing these tiers reduces total storage cost by 60–80% versus a single-tier design.
Step 4 — Validation and cleaning. Enforce schema at ingestion — wrong field types get rejected, not silently coerced. Run range-check filters: a temperature sensor reporting -200°C in a 20°C environment is a fault, not data. Deduplicate aggressively for retry scenarios where devices resend the same message twice during reconnection. Skip this step and you poison every downstream model. Practitioners consistently report that data quality issues — not algorithm choice — are the dominant failure mode in industrial ML.
Step 5 — Streaming vs. batch processing. Streaming pipelines (Kafka, Kinesis, Pulsar) feed sub-minute alerting and live dashboards. Batch pipelines (Spark, dbt on the data lake) handle daily aggregations, training-set preparation, and regulatory reporting. Most production deployments need both — streaming for operations, batch for analytics and ML. The ARDURA seven-layer model frames this dual processing as a standard component of production architecture, not an advanced pattern reserved for hyperscale deployments.
Layer Predictive AI Onto Your IoT Data — The 2026 Baseline
Monitoring is table stakes. Predictive analytics is the ROI engine. The 2026 IoT Developer Roadmap educator states the position explicitly: data analytics and AI skills are no longer optional for IoT developers. If your iot development program ends at dashboards, you have built an expensive monitoring system and called it a transformation.
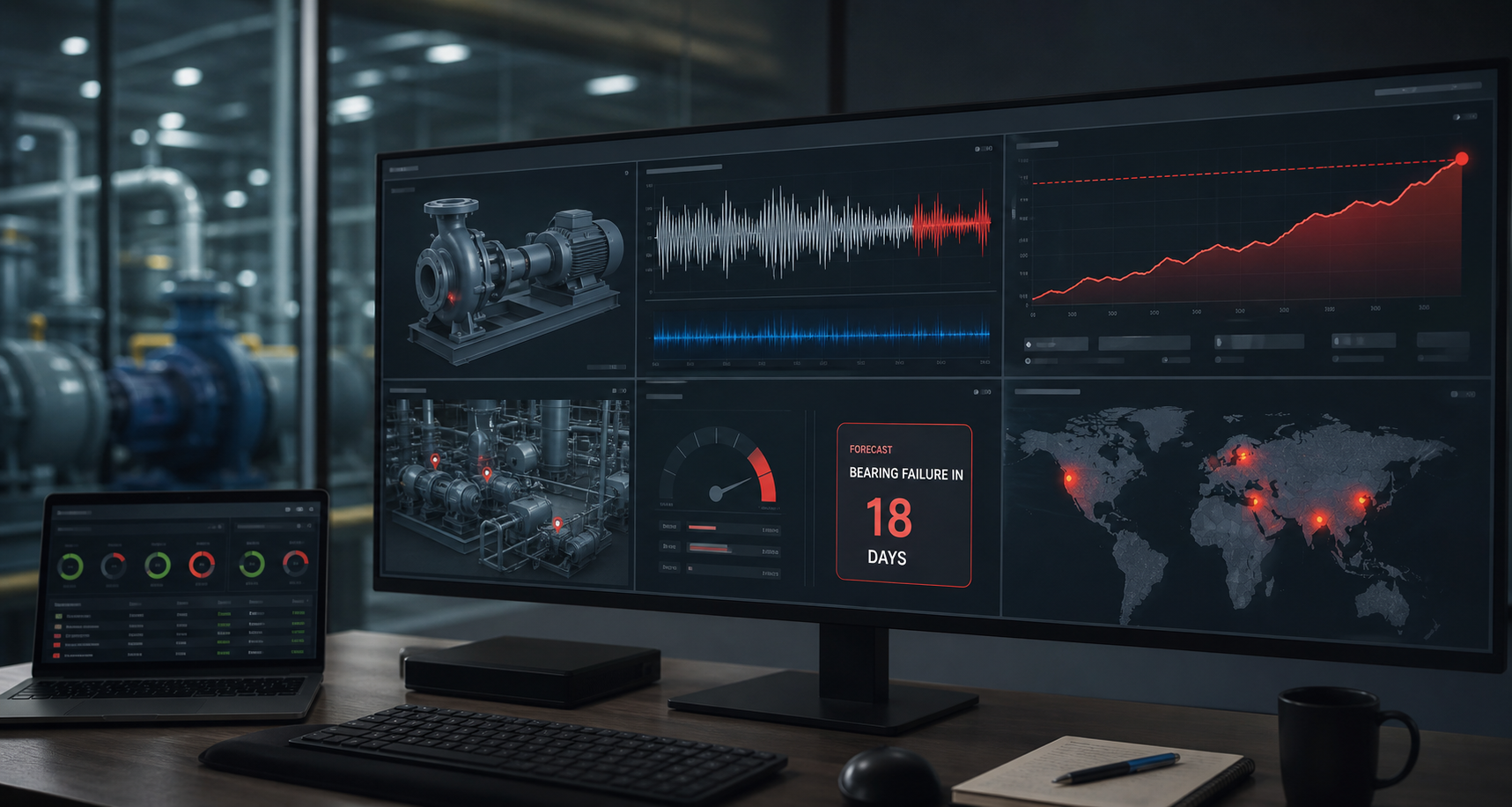
Three model categories deliver the highest production ROI when paired with industrial telemetry, and they should be deployed in order of data maturity. Mature AI solutions and machine learning capabilities integrated with your IoT stack only deliver returns when the underlying data is clean — which is why this section follows pipeline engineering, not precedes it.
Predictive maintenance consumes vibration, temperature, acoustic, and current-draw signatures and feeds them into LSTM networks or gradient-boosted models that flag component degradation 14 to 30 days before failure. The typical industrial applications are bearings, pumps, conveyor motors, gearboxes — components with known failure modes and physical signatures that change as wear accumulates. The requirement that most programs underestimate is the training corpus: you need 6 to 12 months of labeled historical data including at least 3 to 5 actual failure events to train a model that produces trusted predictions. Without that corpus, the team is collecting data, not predicting anything. The honest deployment sequence is monitoring first, baseline collection second, prediction third.
Anomaly detection uses unsupervised models — isolation forests, autoencoders, statistical process control — to flag process drift without requiring labeled failure data. This makes it the right first ML deployment when historical failure data is sparse, which is the situation in roughly every greenfield IoT program. Anomaly detection catches calibration drift, sensor degradation, and out-of-spec process conditions early enough that operators can investigate before the underlying issue becomes a failure. It is less impressive in demos than predictive maintenance, but it delivers value within weeks of deployment instead of months.
Optimization models apply reinforcement learning or constraint-based optimization to energy consumption, HVAC scheduling, fleet routing, and production sequencing. Higher complexity, higher payoff. These typically deploy 12 to 18 months after monitoring is stable, because they require both clean telemetry and a well-defined objective function — and the objective function usually takes longer to specify than the model takes to train.
Raw sensor data is operational noise until a prediction layer turns it into a decision — without that layer, an IoT deployment is just an expensive monitoring system.
The edge AI versus cloud AI trade-off is shifting. IoT Analytics forecasts that AI-aware EDA flows and off-the-shelf AI IP subsystems will see wider adoption in IoT chip development by 2026, making on-device inference increasingly feasible without exotic hardware. Edge inference using TensorFlow Lite or ONNX Runtime on Jetson or Coral hardware delivers sub-50ms latency, but the model complexity ceiling is real — quantized models lose roughly 1–3 percentage points of accuracy versus full-precision cloud versions. Cloud inference handles larger transformer or ensemble models but adds round-trip latency and per-inference egress cost. The standard production pattern is to retrain in cloud and deploy quantized models to the edge, refreshing the deployed model on a quarterly or trigger-driven cadence.
Telnyx identifies AI tightly integrated with IoT data as a primary 2026 trend, particularly around predictive maintenance and real-time monitoring. The market narrative is well-aligned with practitioner experience, with one caveat: vendor content emphasizes opportunity and rarely publishes failure rates. Read between the lines.
The common failure mode bears stating directly. Organizations build ML pipelines before they have clean, labeled historical data. The result is a model that learns from noise and generates alerts no operator trusts. Operator trust, once lost, takes 6 to 12 months to rebuild — usually after the model is rebuilt from scratch with better data. The correct sequence is: clean pipeline first, then 6 to 12 months of baseline collection, then model deployment with operator-in-the-loop feedback to refine alert thresholds. Compress this sequence at your own cost.
Evaluate IoT Platforms and Frameworks Against Your Actual Constraints
Platform selection comes after architecture and hardware decisions, not before. Reversing the order forces architecture to bend to platform limitations — and platform limitations are usually less negotiable than the architecture they end up distorting. By the time you evaluate platforms, you should already know your edge/cloud split, your protocol stack, your data volume per device, and your security non-negotiables.
The landscape splits into two camps with a hybrid middle ground that increasingly dominates.
| Platform | Type | Best Fit | Pricing Model | Ops Burden |
|---|---|---|---|---|
| AWS IoT Core | Managed cloud | Teams on AWS; fast time-to-market | Per-message + egress | Low |
| Azure IoT Hub | Managed cloud | Enterprises on Microsoft stack | Per-device tier | Low |
| ThingsBoard | Open-source AEP | Self-hosted, full data ownership | Free CE / licensed PE | High |
| Mainflux | Open-source | Microservices-first deployments | Free | High |
| EMQX | Open-source MQTT broker | High-scale broker layer (1M+ connections) | Free / enterprise tier | Medium |
Managed cloud IoT services — AWS IoT Core, Azure IoT Hub — offer rapid time-to-market, integrated device shadows, OTA tooling, and native brokers. The cost is egress that scales with fleet size and vendor lock-in at the device SDK level. Note that Google Cloud IoT Core was deprecated; teams that built on it have been retrofitting alternatives for two years, which is the canonical cautionary tale about hyperscaler dependency in this category.
Open-source IoT platforms and Application Enablement Platforms (AEPs) include ThingsBoard, Mainflux, Cumulocity (commercial plus OSS), ThingWorx, Losant, and DataCake. The Mahmood Fathy GitHub roadmap catalogs this ecosystem as a major architectural choice rather than an afterthought. These platforms offer portability, no per-message billing, and full data ownership — at the cost of operational burden and required in-house platform expertise. You are operating infrastructure, not consuming a service.
Hybrid stacks are the 2026 norm. A representative pattern: EMQX or Mosquitto at the edge for local broker resilience, paired with AWS IoT Core for cloud-side device registry and analytics integration. ARDURA reinforces this layered framing as a default production pattern rather than an advanced configuration.
Language and framework choices follow platform decisions. Python dominates rapid prototyping, data engineering, and ML training. Go wins for backend services, broker extensions, and performance-sensitive APIs. Rust is replacing C and C++ in new gateway projects where memory safety is a hard requirement. C and C++ remain dominant for constrained MCU firmware and RTOS integration. Node.js and TypeScript power web-connected device APIs and dashboards, with Node-RED frequently used for visual flow logic in pilots. Most production teams end up running two or three of these languages — the firmware language and the cloud language rarely match.
The decision framework is simple but rarely applied. Managed cloud beats open-source when the team is small, has no dedicated platform engineers, the fleet stays under roughly 50,000 devices, and the organization can absorb egress costs as a known operating expense. Open-source wins when data residency requirements rule out external clouds, fleets exceed roughly 100,000 devices and per-message pricing becomes punitive, or regulatory environments require data to stay inside a controlled boundary. Most enterprises end up hybrid: managed cloud for registry and analytics, self-hosted EMQX or Mosquitto at the regional edge for resilience and cost control. When neither off-the-shelf option fits the constraint stack, custom software solutions built on open-source primitives become the rational answer — but only after you have proven the off-the-shelf options cannot work.
Build Security, Compliance, and Maintenance Into the Design — Not the Backlog
IoT educational content historically under-covers security relative to connectivity, and that gap is where most production programs accumulate technical debt. The GitHub roadmap and the full-stack IoT engineer video devote extensive space to protocols, brokers, and cloud platforms — and comparatively thin coverage to secure boot, firmware signing, and SBOM hygiene. OTG Consulting frames IoT as part of the broader 2026 security roadmap, not a separate workstream bolted on after deployment. The argument extends naturally: comprehensive cybersecurity solutions must encompass device endpoints and telemetry channels from the architecture phase forward.
Seven non-negotiables. Each should appear as an acceptance criterion in the architecture decision record, not a Phase 2 backlog item.
- Device-level hardening. Secure boot with hardware root of trust, signed firmware images, and encrypted credentials stored in TPM or secure elements (ATECC608, NXP EdgeLock). Devices without secure boot can be re-flashed in the field and weaponized — used as botnet nodes or pivots into the OT network. This is a hardware specification decision, made during the procurement covered in the second section, not a software fix layered on later.
- In-transit encryption. TLS 1.3 or mTLS for all device-to-cloud communication. Mutual TLS is mandatory for any device that controls physical actuators — pumps, valves, motors, breakers. Plan certificate rotation before deployment, not after. Expired certificates across 50,000 devices is an operational crisis, not a calendar event.
- Data governance and residency. Map where each data class lives — raw telemetry, derived metrics, personally identifiable cross-references — against GDPR, HIPAA, and regional data residency rules. Encryption at rest using KMS-managed keys is the floor. Define retention policies per data class before the first byte hits storage, because retroactive purging across multi-tier storage is painful and frequently incomplete.
- Role-based access control. Which devices can publish to which topics? Which operators can issue actuator commands versus read-only telemetry? Enforce through broker ACLs and cloud-side IAM with default-deny posture. Most IoT breaches in regulated industries trace to overly permissive broker configurations set during the pilot and never tightened.
- Telemetry on the telemetry. Log broker connection failures, anomalous publish rates, and unexpected geolocations as security events. The fastest detection signal for a compromised device fleet is metric anomalies on the IoT infrastructure itself — a sudden spike in publish volume from a quiet sensor class, or connections originating from unexpected IP ranges.
- OTA update strategy. Staged rollouts (1% → 10% → 100%), atomic A/B partition updates with automatic rollback on health-check failure, signed update payloads. Plan maintenance windows that respect operational schedules — a refinery cannot accept firmware updates during a turnaround, and a hospital cannot accept them during code response.
- Vendor and component vulnerability tracking. Require Software Bills of Materials (SBOMs) from every chipset, RTOS, and broker vendor. Subscribe to CVE feeds for each component. A vulnerability in a widely-deployed MQTT library becomes your problem within 48 hours of disclosure. Forward-looking deployments are evaluating blockchain-based device identity and tamper-evident supply chain audit trails as the next layer of provenance assurance for high-value or regulated device fleets.
Organizations that integrate these requirements during architecture and hardware specification avoid 6 to 12 months of retrofit work. Those that defer them treat security as a perpetual project — the kind that consumes engineering capacity without producing visible deliverables, and that quietly determines whether the program survives its first incident.
Most IoT programs do not fail because the cloud doesn't scale or the hardware breaks — they fail because security and lifecycle maintenance were treated as Phase 2 work that never started.
Execute the Phased Roadmap — Weeks, Roles, and Go/No-Go Triggers
The prior six decisions translate into a concrete 24-week execution plan with named phases, deliverables, team roles, and go/no-go triggers. Robologics Lab's lifecycle framing — idea → proof of concept → pilot → scalable deployment — anchors the structure. Each phase exists to validate assumptions cheaply before committing capital to the next.
Phase 0 — Architecture and Vendor Lock (Weeks 1–4)
- Run a 2-week architecture workshop using the decision matrix from the first section.
- Specify hardware tiers and connectivity per device class using the hardware checklist.
- Shortlist two IoT platforms (one managed, one open-source) for a PoC bake-off.
- Define security non-negotiables as acceptance criteria, not aspirations.
- Deliverable: Architecture decision record (ADR), hardware bill of materials, platform shortlist.
- No-go trigger: No agreement on edge versus cloud split. Stop and escalate before procuring hardware. Procuring on a contested architecture decision wastes capital and forecloses options.
Phase 1 — Pilot Deployment (Weeks 5–12)
- Procure 10 to 50 devices across representative use cases — pick the cases that exercise the architecture, not the easiest ones.
- Deploy edge gateways, MQTT broker, and time-series storage end-to-end.
- Begin baseline data collection. No ML yet. Resist pressure to demo predictions.
- Run a penetration test against device and broker before scaling. Findings here cost roughly 1/20th what they cost in production.
- Deliverable: Working pilot, 60+ days of clean baseline data, pen-test report.
- No-go trigger: Connectivity reliability under 95%, or sensor data quality below validation thresholds. Re-evaluate hardware before scaling — the failure compounds at fleet level.
Phase 2 — Data Pipeline and First Model (Weeks 13–20)
- Build the full ingestion → storage → analytics pipeline following the five-step sequence.
- Deploy anomaly detection as the first ML model. Lower data requirement than predictive maintenance, faster to operator trust.
- Complete security audit against the seven non-negotiables.
- Integrate with operational dashboards in the tools operators already use, not a new portal.
- Deliverable: Production-grade pipeline, first model in operator hands, security sign-off.
- No-go trigger: Operators ignore model alerts as noise. Retrain on labeled feedback before expanding model scope or deployment footprint.
Phase 3 — Scale and Continuous Improvement (Weeks 21+)
- Roll out to full fleet in staged waves (10% → 50% → 100%).
- Deploy predictive maintenance models once labeled failure data exists — typically 6 to 12 months into baseline collection.
- Establish OTA cadence, model retraining schedule, and disaster recovery testing as recurring operations.
- Deliverable: Full fleet operational, documented runbooks, defined ownership for every layer.
- Ongoing: Quarterly model performance review, annual security re-audit, semi-annual hardware refresh evaluation.
Resource Matrix
| Role | Phase 0 | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|---|
| IoT Architect | Lead | Advisory | Advisory | Advisory |
| Embedded Engineer | Spec | Lead | Support | Support |
| Cloud/Backend Engineer | Spec | Lead | Lead | Support |
| Data Engineer | — | Setup | Lead | Lead |
| ML Engineer | — | — | Lead | Lead |
| Security Engineer | Spec | Audit | Audit | Continuous |
| DevOps/SRE | Setup | Setup | Lead | Lead |
The pattern in this matrix is the inversion that most programs get wrong: architecture and security must be involved from week one and become advisory rather than vanish, while data and ML capacity must exist before Phase 2, not after the pipeline is already producing data that nobody is modeling.
Risk Trigger Cheat Sheet
- Hardware qualification failures in pilot → re-spec the device class, do not scale on the assumption it will work at volume.
- Latency SLA missed by more than 20% → revisit architecture; you likely need more edge processing than originally specified.
- Data quality issues affecting more than 5% of records → fix pipeline validation before adding any ML capability.
- Security finding rated High or Critical → halt rollout until remediated. Do not negotiate exceptions.
- Operator trust in alerts below 70% → retrain or recalibrate models before adding new ones. New models on distrusted infrastructure inherit the distrust.
The phasing in this roadmap is deliberately conservative because the failure cost asymmetry is severe: a six-week delay in pilot is recoverable; a six-month retrofit of architecture in production is rarely budgeted and frequently fatal to the program's political support. For organizations that need accelerated decision-making across architecture, platform, and security simultaneously, Lagodish Tech's IoT discovery engagement compresses Phase 0 into a structured two-week workshop with an architecture decision record as the deliverable.